
最近,GLM 5.2 接连刷屏,国产模型又热闹起来了。
加上 DeepSeek V4、MiniMax M3,还有阶跃星辰的 Step-3.7-Flash,国产大模型这一波可以说是你追我赶,热度一下子又上来了。
可能有小伙伴对阶跃模型不熟悉哈,阶跃也是AI六小虎之一。

对于我们这些AI博主来说,日常就会使用到这些模型。针对这几个模型的使用大体分为两类。
「Pro/旗舰」和「Flash/效率型」两类
Pro/旗舰:能力上限更高

这一档代表的是各家最强模型,通常适合复杂推理、长链路规划、多轮任务拆解、代码架构设计、深度研究这类场景。
Pro 档可以理解为各家模型里的旗舰能力层,主要面向复杂推理、代码工程、长链 Agent 和高价值任务。海外代表包括 GPT 旗舰系列、Claude Opus、Gemini Pro;国内则可以对应 DeepSeek Pro 系列、千问 Max、高能力版 Kimi、豆包旗舰模型,以及 GLM 的高能力版本。
这类模型的优势是能力强、稳定性高、理解复杂任务更稳。但代价也明显:成本更高、速度未必最快。
Flash/效率型:模型能力的平衡点

Flash 档更适合生产环境里的高频调用。
它不一定追求所有榜单第一,但要做到三件事:响应快、成本低、任务完成率稳定。
在各种Agent调用,比如数据处理Agent,办公Agent等等。需要连续性,成本控制的模型。
它不是“低配版 Pro”,准确说是面向效率型 Agent 场景的独立品类。
测试一下实际效果怎么样。
工具选用Trae。全局使用统一的Trae设置,同一个项目。
每个模型都单独跑一遍,测试开始前,项目环境和缓存状态保持一致。
制作项目测试集,查看模型在高频任务,代码质量,速度这些方面的能力。
Step-3.7-Flash
更适合放进 Agent 工作流里。
之前做了一个新闻收集项目,需要开发一些测试类来对接口进行测试稳定性。
先让AI整理一下测试提示词。


把准备好的提示词先丢给他。
差不多5分钟的时间,测试类就生成好了。

优化一下依赖,Agent自动进行了42次测试。
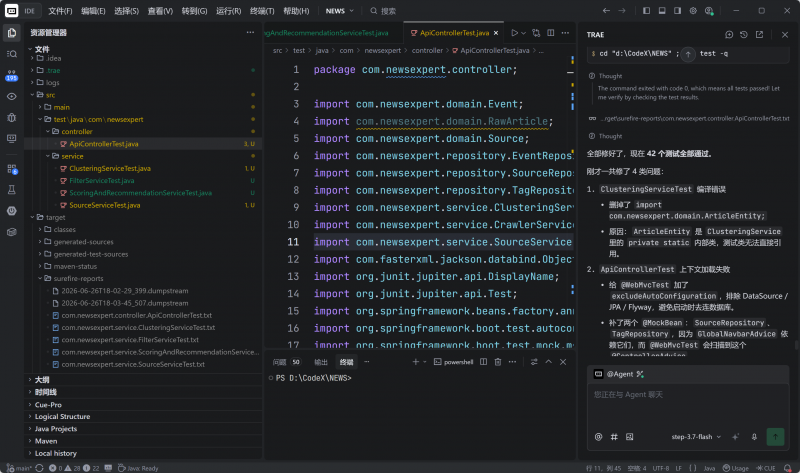
差不多一次性完成了80%,因为有些依赖问题,进行了二次检测和修改。
代码量在900行左右。
消耗token输入和输出合计在500万左右。

消耗金额在3.5元左右。
然后我们用GPT5.4模型来进行同样的测试。
GPT5.4
GPT5.4属于Pro档模型。
同样的任务,GPT写的代码质量相对要好一点,中间没有二次优化,对于代码测试集来说,两者差距并不大。
这种测试类型的代码相对比较简单,主要就是看模型的多路书写能力。
GPT5.4的消耗就要比Step-3.7-Flash高出不少。因为GPT5.4需要长思考,所以对于简单高频的任务来说,时间上可能会比较慢。
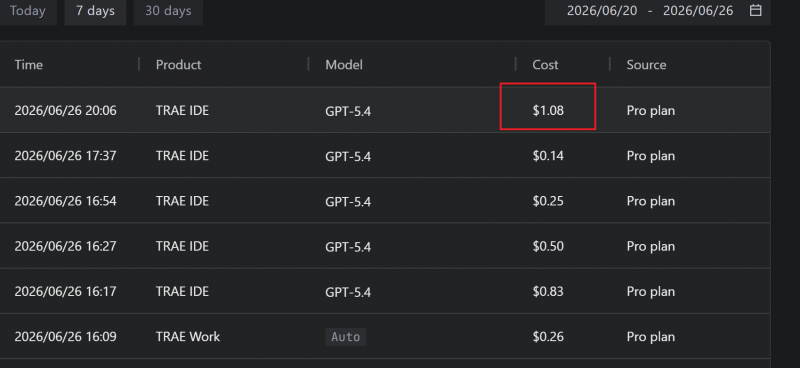
在Trae的资源管理里面,可以看见这次消耗了1美元,那差不多就是Step-3.7-Flash的两倍用量。国外的模型本来就比较贵,中国模型有天然的优势。
效果差不多是GPT5.4的90%,成本为GPT5.4的1/2。
Deepseek-V4-Flash。
Deepseek 就不用多介绍了,属于很多人接触国产大模型的第一站。
它最大的特点不是花里胡哨,而是稳定、便宜、生态成熟。你平时写文章、改文案、做资料整理、写代码、做方案,大部分场景它都能顶上。
如果说其他模型有些是偏专项能力,Deepseek 更像一个通用底座。
这里采用deepseek-V4-Flash。
同样在Trae里面测试这个模型生成测试集代码的质量和实效。
几分钟后文件就创建好了。
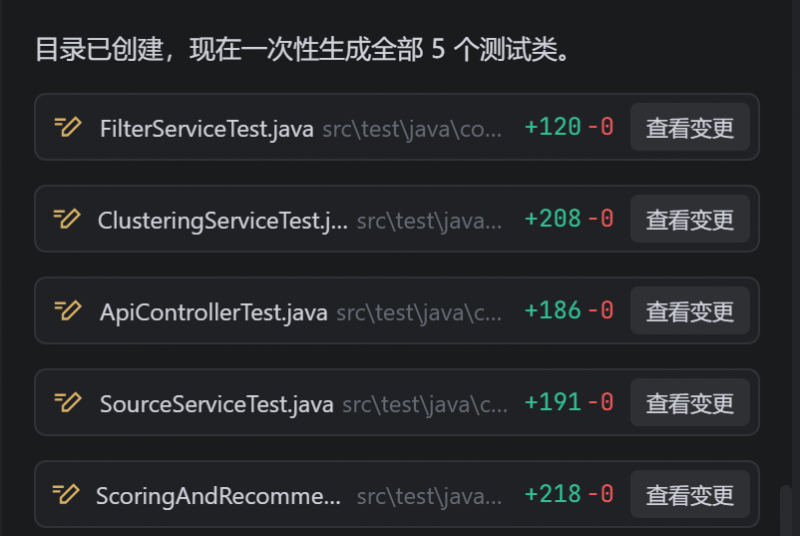
有一个小问题,代码也有一部分报错信息,需要二次调整。
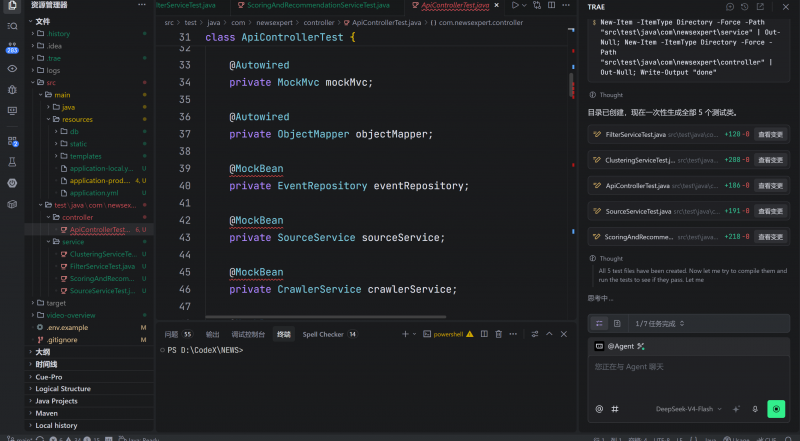
生成的代码质量还可以,测试链路也可以跑通,只不过有一个小问题,就是deepseek-V4-Flash自己写的代码进行测试的时候,消耗时间要比前面这两个模型长一些,可能是测试内容比较多。
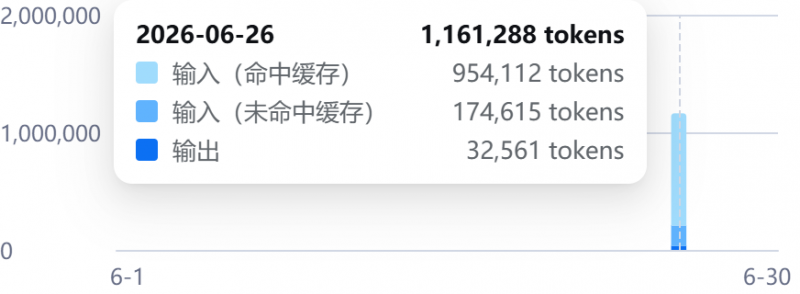
消耗了120万左右的token,费用在0.2元左右,没办法,deepseek价格的确是他最大的优势。
GLM5.2
GLM5.2属于Pro档模型。
GLM5.2 更适合放在长任务和 AI Coding 场景里看。
这类模型不能只看它会不会聊天。更关键的是,它能不能在一个比较长的任务里坚持跑下去。
比如让它读完整项目代码,理解目录结构,分析问题在哪里,然后一步步修改、测试、继续修。这个过程对模型要求很高。上下文不够,前面看过的东西后面就忘了;工具调用不稳,跑一半就断;规划能力不行,很容易改着改着跑偏。
GLM5.2 的定位就很明显:长上下文、长任务、Agent 工作流。
同样的任务进行测试看看效果如何。总体运行时间在15分钟左右,这就是Pro模型的特点,能力强没的说,但在实效上肯定就要落后一点。
需要的测试代码也是正常生成的。
Agent自动帮我们进行了测试。对每个类别进行了多次测试。
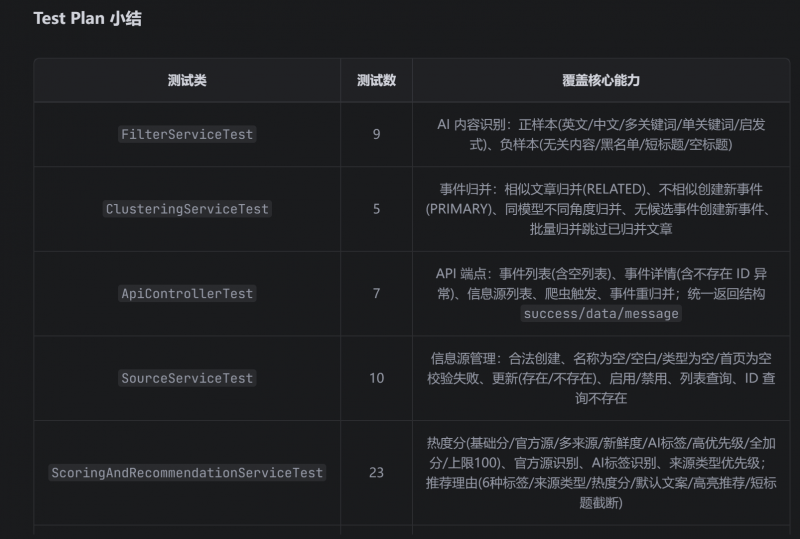
测试中有一个失败。Agent识别后也是快速得到了修复。

但是GLM5.2有一个很明显的问题,就是不稳定,不稳定是因为使用的人太多了有时候要排队,其次就是价格问题。
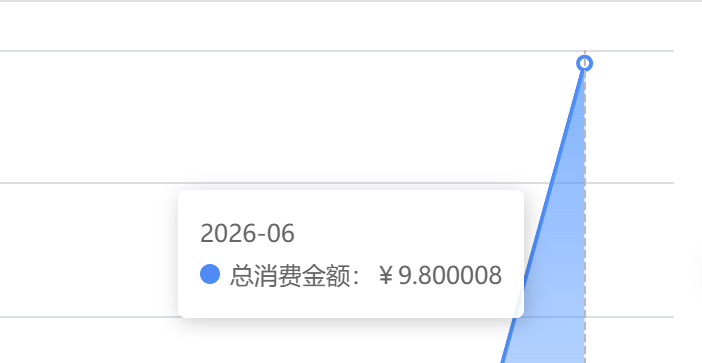
这个任务消耗了9.8,但实际消耗了12块左右。
我也打算尝试使用聚合平台来测试,在聚合平台上面使用gemini-3.5-flash,来进行测试。但测试到一半就不行了,因为太贵。我以为十元可以跑完这个测试,但是跑一半就提示余额不足了。
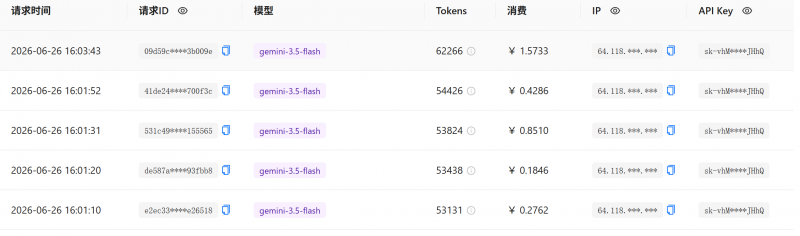
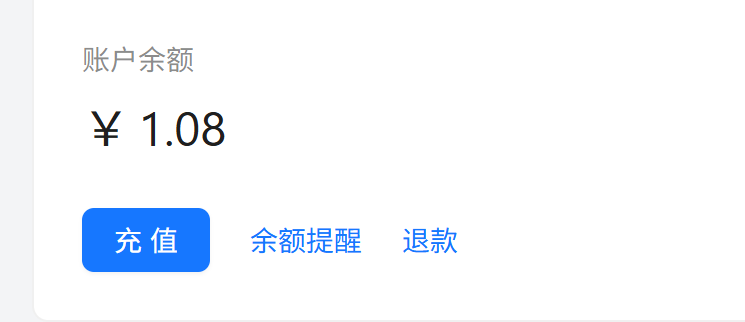
而且利用聚合平台还有一个问题就是不稳定。

最后
所以这篇测下来,我对 Step-3.7-Flash 的定位会更清楚一点。
它不是去和 Pro 档硬拼极限推理,也不是去和效率档拼最低单价。它更像是卡在中间那个最实用的位置:速度够快、成本能控、稳定性也能支撑连续任务。
尤其是生产级 Agent 场景里,这个优势会更明显。比如高频调用、多轮执行、低延迟响应、代码测试、数据处理、办公自动化,再加上一些多模态输入,这类任务并不一定需要最强模型,但一定需要模型跑得快、跑得稳、跑得便宜。
从这个角度看,Step-3.7-Flash 更像是“效率前沿”赛道里的综合最优解。
如果你的任务是复杂长链推理、深度研究、架构级代码设计,那还是优先选 Pro 档。但如果是日常生产环境里的高频 Agent 工作流,我会更倾向于先把 Step-3.7-Flash 放进候选名单里。
标题:别只盯着最强模型了,Agent 场景更该看这类 Flash 档模型
地址:http://www.ictaa.cn/hlwjj/60138.html

